AMD ha anunciado oficialmente la nueva generación de la serie Radeon, que llevará el número 7000 detrás de la designación RX. Por supuesto, los modelos superiores llegan primero y utilizan la nueva arquitectura RDNA 3, que brilla especialmente en términos de eficiencia energética en comparación con su predecesor ya frugal. Por supuesto, el hecho de que el nuevo diseño, cuyo nombre en código es Navi 31, esté basado en nodos TSMC de 5 y 6 nm es de gran ayuda. Esto no es un error tipográfico, AMD ya usa dos tecnologías de producción, ya que son los primeros en la industria en introducir un diseño de chiplet ya instalado para procesadores a GPU.
En el caso de las GPU, AMD se comportó exactamente al revés que con los procesadores, mientras que en Ryzens los chips de la CPU se colocan alrededor del chip IO, mientras que en las GPU colocan los llamados MCD (Memory Cache Die) en One GCD (Graphics). Computation Template), es decir, al lado del chip GPU. El GCD de 300 mm², cuyo nombre en código es Navi 31, se fabrica según el proceso de 5 nm de TSMC, y junto a él hay seis MCD, cada uno de 37 mm², fabricados en un nodo de 6 nm. Según AMD, la cantidad total de transistores es de 58 mil millones, pero no explicaron por separado cuánto se usan solo el GCD y el MCD.


 [+]
[+]
Los chiplets están conectados por Infinity Fabric complementado por la segunda generación de Infinity Cache, con un rendimiento total de transferencia de datos de 5,3 TB/s, lo que la convierte en la interfaz de tejido más rápida de la actualidad. Cada uno de los MCD contiene un canal de memoria de 64 bits, un controlador de memoria que admite memoria GDDR6 estándar, un chip Infinity Cache de 16 MB y la interfaz Infinity Fabric necesaria para comunicarse con el GCD. El concepto tiene sentido aquí porque, en términos de tamaño físico, la mayoría de este chip es un circuito de E/S y caché, que no puede escalarse de manera óptima, por lo que vale la pena fabricarlo en un nodo de 6 nm, porque difícilmente será más pequeño. que 5nm que el mismo chip, mientras que el costo de producción aumentará varias veces. Esto le ahorra prácticamente a AMD el uso de un costoso proceso de 5 nm para al menos algunos de los circuitos necesarios para alimentar el sistema, lo que significa que ganan mucho en términos de costos de producción, que obviamente apartarían en parte como ganancias y en parte podrían cotizar. Más libremente.
Con respecto a Infinity Cache, se puede ver que su capacidad ha disminuido en comparación con RDNA 2, lo que AMD explica por el hecho de que la tasa de aciertos ha mejorado en la versión de segunda generación. Había una buena posibilidad de resolver este problema, porque la Infinity Cache de primera generación en realidad no era más que engordar el caché L3 de la víctima, que simplemente se extrajo del diseño Zen. Su funcionamiento no estaba nada optimizado para la GPU, pero básicamente hacía lo que se necesitaba. La segunda generación ya se ha convertido en una caché optimizada para el funcionamiento de la GPU. Aunque la caché de la víctima se mantiene, está más adaptada a que no solo unos pocos, sino una gran cantidad de procesos independientes se ejecutan dentro de la GPU, por lo que su estructura se adapta a este uso. Por eso, basta con construirlo con una capacidad menor, porque habrá muchos menos casos de pérdida de caché.
AMD también rediseñó el sistema dentro del GCD. En primer lugar, vale la pena echar un vistazo rápido a la nueva pantalla y al motor multimedia. La sorprendente innovación del primero es que admite la interfaz DisplayPort 2.1, pero de hecho también se ha modificado dentro de este, ya que ahora puede manejar un ancho de banda de 54 Gbps y 12 bits por canal de color, lo que significa que garantiza una visualización de hasta 68 mil millones de colores En total. La compañía lo llamó Radiance Display Engine, y realmente es el motor más alto disponible en el mercado, e incluso puede ejecutar pantallas de 8K a 165 Hz, y las pantallas de 4K pueden llegar hasta los 480 Hz. Según la compañía, los monitores que utilizan la entrada DisplayPort 2.1 también estarán disponibles el próximo año.


 [+]
[+]
También se mejoró el motor multimedia, pero conservó el nombre VCE, es decir, el motor de codificación de video. Además, Navi 31 en realidad no tiene uno, sino dos motores multimedia que pueden funcionar en paralelo, es decir, la codificación y decodificación en formatos HEVC, H.264 y AV1 se pueden realizar al mismo tiempo. En el caso de este último, estará disponible la calidad 8K que entrega 60 cuadros por segundo, además, el sistema también incluirá una línea de ensamblaje de codificadores de IA, que pueden mejorar la calidad de grabación o transmisión.
Pasando a la arquitectura, AMD no ha revelado mucho al respecto, pero ciertamente se ha producido una revisión bastante importante respecto a RDNA 2. Por otro lado, a partir de ahora, la CU, o multiprocesadores en general, tiene áreas de grabación. veces y media más, que aumentó principalmente por el cambio del anterior par de bloques SIMD de 32 vías también. El sistema tiene el llamado diseño de liberación dual, lo que significa que no solo se puede ejecutar una instrucción, sino dos instrucciones independientes para cada señal de reloj cuando se ve en un componente de sombreado. Esto no es muy fácil de entender, pero Modelo de clasificación de Flynn Teniendo en cuenta que el procesador SIMD se ha convertido en MIMD en determinados modos de funcionamiento. Esto simplemente significa que un componente de sombreado puede realizar una operación en los datos de entrada, luego otra operación en su resultado e imprimir el resultado en el mismo ciclo. Es posible y, de hecho, seguro que AMD creó esto para el trazado de rayos, porque las tareas relacionadas con el recorrido usan mucha multiplicación sobre el resultado de un proceso determinado, que RDNA 3 puede hacer casi gratis. El diseño de la versión dual también podría ser útil en otros lugares, pero el código debe configurarse a nivel de concepto, por lo que el trazado de rayos en general es casi ideal para este diseño. Además, la CU también obtiene dos motores de IA, lo que también es una innovación, y se ha mejorado el rendimiento del componente de seguimiento de paquetes. También nos gustaría señalar que, a partir de ahora, AMD nuevamente se referirá a los multiprocesadores como CU, pero esta CU no es la misma CU que era en los diseños anteriores de RDNA, por lo que una comparación directa de la cantidad no tiene sentido.
El objetivo principal de AMD era mejorar la eficiencia energética, que prometieron en un 50%, y terminó siendo un 57% en comparación con RDNA 2. El hecho de que también tocaron el sistema anterior en términos de relojes juega un papel en esto. Anteriormente, todos los procesadores funcionaban con el mismo reloj base, pero en RDNA 3 no será así. Las CU, es decir, el sombreador y el front-end del chip, es decir, principalmente los motores de comando, así como el transformador raster y la línea de montaje de ingeniería, pueden funcionar a diferentes horas. En términos de reproducción, AMD continúa brindando la llamada señal de reloj Boost, que básicamente será el máximo que se puede configurar para cada componente. Además, el reloj del juego seguirá significando la frecuencia a la que normalmente se ejecutan las CU en los juegos, pero todo lo demás ahora puede recibir el reloj de impulso. Según la compañía, esto era necesario porque los juegos de hoy en día suelen estar limitados en términos de interfaz, por lo que ayuda a aliviar un poco ese límite.
Los parámetros conocidos de los nuevos VGA de AMD se detallan en la siguiente tabla:
| escribe | 7900XT | 7900XTX |
|---|---|---|
| Nombre del código de la GPU | Navegación 31 | |
| Ingeniería general | ARN 3 | |
| GPU de juego/reloj de impulso | 2000/2400 MHz | 2300/2500MHz |
| número de unidades de trabajo | 84 | 96 |
| Número real/efectivo de componentes de sombreado | 5376/10752 | 6144/12288 |
| Número de canales de instalación | 336 | 384 |
| número de unidades de mezcla | 192 | 192 |
| Tasa de relleno de píxeles | 460,8 Gb/s | 480 GB/s |
| Velocidad de llenado de Texel | 806.4 GTexels/seg | 960 GTexels/seg |
| Potencia informática teórica (FP32) | 52 TFLOPS | 61 TFLOPS |
| dinero en efectivo | 80 MB | 96 MB |
| Ancho de banda de caché infinito | 2900 GB/seg | 3500 GB/s |
| bus de memoria | 320 bits | 384 bits |
| reloj de memoria activa | 20 GHz | 20 GHz |
| tipo de memoria | GDDR6 | |
| Ancho de banda de memoria | 800 GB/s | 960 GB/s |
| TBP consumo | 300 vatios | 355W |
| Conectores de alimentación PCI Express | 8 + 8 pines | 8 + 8 pines |
| Conector PCI Express | x16 PCI Express 5.0 | |

 [+]
[+]
En cuanto a salidas, los modelos de referencia de AMD contarán con un puerto HDMI 2.1, un DisplayPort 2.1 y un puerto USB tipo C. En este último caso, cabe destacar que tiene una incidencia importante en el consumo máximo teórico, ya que también puede transmitir energía al dispositivo conectado. Esto se incluye en el valor TBP dado, ya que incluye el consumo de energía desde el punto de vista de VGA. Según nuestra información, es de 30 a 40 vatios para ambos modelos, por lo que el consumo de TBP sin uso activo del tomacorriente es casi mucho menor.
[+]
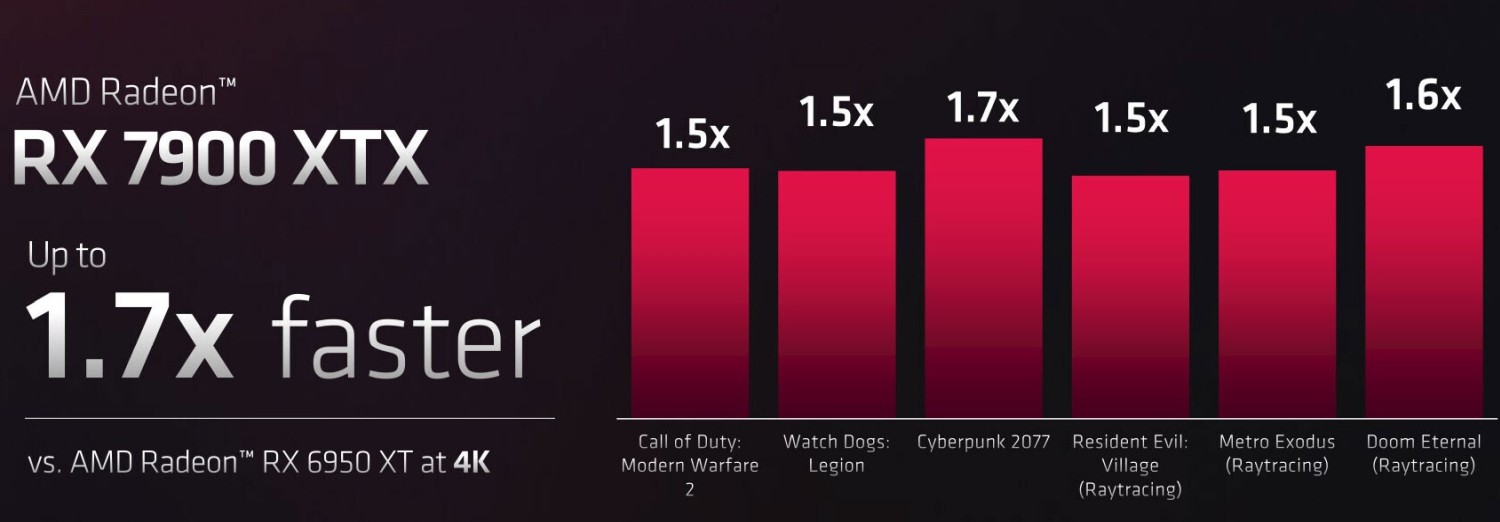
Según AMD, la Radeon RX 7900 XTX es un 50-70 % más rápida que la Radeon RX 6950 XT en varios juegos con una resolución de 4K. Es difícil extraer más que eso de los datos en este momento.
Las Radeon RX 7900 XT y 7900 XTX anunciadas llegarán el 13 de diciembre por $899 y $999, respectivamente.

«Certified foodie. Extreme internet guru. Gamer. Bee addict. Zombie ninja. Problem solver. Unapologetic alcohol lover.»